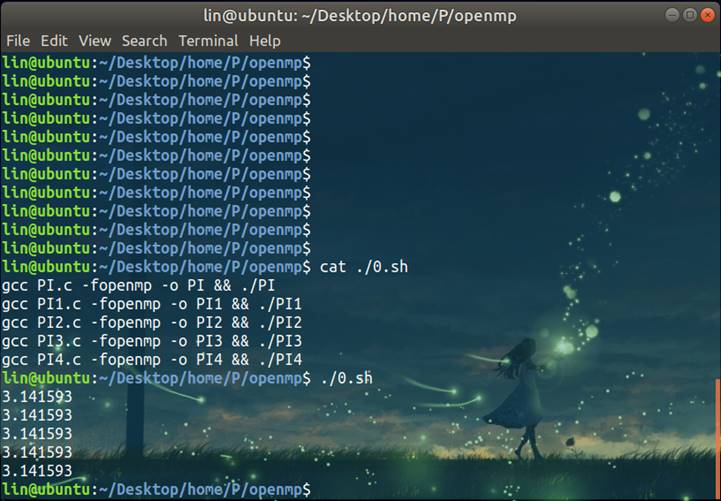
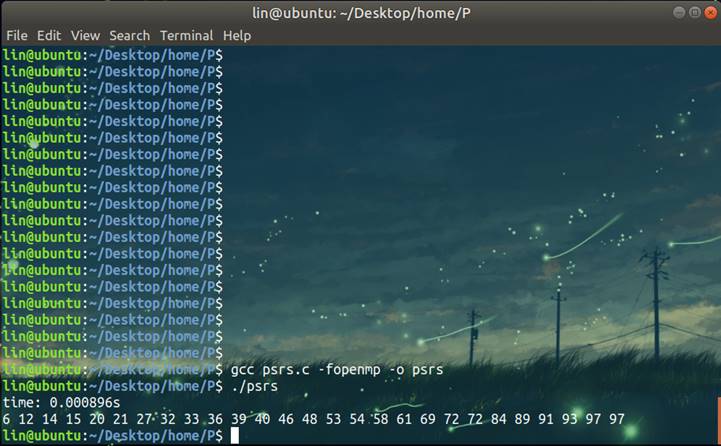
题目
OpenMP实现π值的计算和PSRS排序
算法设计
π值的计算
基本的串行算法

利用公式arctan(1)=π/4以及(arctan(x))’=1/(1+x^2),在[0, 1]上对f(x)= 4/(1+x^2)求积分,使用积分的定义离散化近似求解。将[0, 1]分成大量的小区间,使用for循环在每个小区间上计算y_i的值,最后求和。
使用并行域并行化的程序
在基本的串行算法上,用编译制导语句#pragma omp parallel将y_i的计算并行化(注意将使用到的变量私有化,每个线程各自拥有),显式地分配for循环,将紧挨着的p个区间的y_i的值分配给p个处理器分别计算(而不是将全部区间直接划分给p个处理器,这样可能导致各线程负载不均衡)。退出并行域之后,主线程对p个处理器各自的局部和sum进行求和。
使用共享任务结构并行化的程序
在基本的串行算法上,用编译制导语句#pragma omp parallel将y_i的计算并行化,但是并不显式地分配for循环,直接在for循环前面加上编译制导语句#pragma omp for,系统将for循环自动分配给p个处理器。退出并行域之后,主线程对p个处理器各自的局部和进行求和。
使用private子句和critical部分并行化的程序
在基本的串行算法上,用编译制导语句#pragma omp parallel将y_i的计算并行化(注意将使用到的变量私有化,每个线程各自拥有),显式地分配for循环,将紧挨着的p个区间的y_i的值分配给p个处理器分别计算(而不是将全部区间直接划分给p个处理器,这样可能导致各线程负载不均衡)。随后,直接在并行域内对上面的结果求和,但必须加上编译制导语句#pragma omp critical,表示指定代码段在同一时刻只能由一个线程进行执行。
使用并行规约的并行程序
在基本的串行算法上,用编译制导语句#pragma omp parallel for reduction(+:sum) 将y_i的计算并行化(注意将使用到的变量私有化,每个线程各自拥有),显式地分配for循环,将紧挨着的p个区间的y_i的值分配给p个处理器分别计算(而不是将全部区间直接划分给p个处理器,这样可能导致各线程负载不均衡)。sum存储了各个处理器的局部和,最后无需主进程显式地对局部和求和,系统将使用指定的算法(+),对各个局部的sum自动归约。
PSRS排序
给定n个元素的数组A[0..n - 1],执行以下步骤
(1)均匀划分:将A[0..n - 1]均匀划分成p段,每个处理器pi处理A[(i*n/p..(i+1)*n/p - 1]
(2)局部排序:每个处理器pi调用串行排序算法对A[(i*n/p..(i+1)*n/p - 1]排序
(3)选取样本:每个处理器pi从自己的有序子数组A[(i*n/p..(i+1)*n/p - 1]中等间距选取p个样本元素
(4)样本排序:用一台处理器对p2个样本元素进行串行排序
(5)选择主元:用一台处理器从排好序的样本序列中选取p - 1个主元,并播送给其他pi
(6)主元划分:每个处理器pi按p - 1个主元将自己的有序子数组A[(i*n/p..(i+1)*n/p - 1]划分成p段,此时,新申请一个数组存放p段数据(每段长度可能不同)
(7)全局交换:每个处理器pi将自己的有序子数组中的每段按段号交换到对应id的处理器中。
(8)归并排序:每个处理器pi对接收到的元素进行归并排序
(9)将各处理器的新数据写回A,此时,原数组A已有序
算法分析
π值的计算
设n为[0, 1]之间划分的区间数
对于串行算法,时间复杂度为O(n)
对于4种并行算法,时间复杂度为O(n/p),其中p为处理器数
PSRS排序
(参考文献 Hanmao Shi , Jonathan Schaeffer. Parallel Sorting by Regular Sampling.)
设n为A的元素个数,p为处理器数,w = n/p
则时间复杂度为各阶段时间复杂度之和
若, 近似为
另外,算法第六步每个处理器的w个数据根据p – 1个主元划分,每段的长度可能不相等,因此数组低维的长度不等,无法实现确定,但文献中证明了每段的长度最长不超过2w个元素。
Theorem 1: In phase 3 of PSRS, each processor merges less than 2w elements.
算法源代码
π值的计算
基本的串行算法
#include <stdio.h>
static long num_steps = 100000;//越大值越精确
double step;
void main(){
int i;
double x, pi, sum = 0.0;
step = 1.0 / (double)num_steps;
for(i = 1; i <= num_steps; i++){
x = (i - 0.5) * step;
sum = sum + 4.0/(1.0 + x * x);
}
pi = step * sum;
printf("%lf\n", pi);
}
使用并行域并行化的程序
#include <stdio.h>
#include <omp.h>
#define NUM_THREADS 2
static long num_steps = 100000;
double step;
void main ()
{
int i;
double x, pi, sum[NUM_THREADS];
step = 1.0 / (double)num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel private(i) //并行域开始,每个线程(0和1)都会执行该代码
{
double x;
int id;
id = omp_get_thread_num();
for(i = id, sum[id] = 0.0; i < num_steps; i = i + NUM_THREADS){
x = (i + 0.5) * step;
sum[id] += 4.0 / (1.0 + x * x);
}
}
for(i = 0, pi = 0.0; i < NUM_THREADS; i++)
pi += sum[i] * step;
printf("%lf\n", pi);
}
//共2个线程参加计算,其中线程0进行迭代步0,2,4,...线程1进行迭代步1,3,5,....
使用共享任务结构并行化的程序
#include <stdio.h>
#include <omp.h>
#define NUM_THREADS 2
static long num_steps = 100000;
double step;
void main ()
{
int i;
double x, pi, sum[NUM_THREADS];
step = 1.0 / (double)num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel //并行域开始,每个线程(0和1)都会执行该代码
{
double x;
int id;
id = omp_get_thread_num();
sum[id] = 0;
#pragma omp for //未指定chunk,迭代平均分配给各线程(0和1),连续划分
for(i = 0; i < num_steps; i++){
x = (i + 0.5) * step;
sum[id] += 4.0 / (1.0 + x * x);
}
}
for(i = 0, pi = 0.0; i < NUM_THREADS; i++)
pi += sum[i] * step;
printf("%lf\n", pi);
}//共2个线程参加计算,其中线程0进行迭代步0~49999,线程1进行迭代步50000~99999.
使用private子句和critical部分并行化的程序
#include <stdio.h>
#include <omp.h>
#define NUM_THREADS 2
static long num_steps = 100000;
double step;
void main ()
{
int i;
double pi = 0.0, sum = 0.0, x = 0.0;
step = 1.0 / (double)num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel private(x, sum, i) //该子句表示x,sum,i变量对于每个线程是私有的
{
int id; //不用定义为私有,因为id是在并行域内定义的
id = omp_get_thread_num();
for(i = id, sum = 0.0; i < num_steps; i = i + NUM_THREADS){
x = (i + 0.5) * step;
sum += 4.0 / (1.0 + x * x);
}
#pragma omp critical //指定代码段在同一时刻只能由一个线程进行执行
pi += sum * step;
}
printf("%lf\n", pi);
}
//共2个线程参加计算,其中线程0进行迭代步0,2,4,...线程1进行迭代步1,3,5,....
//当被指定为critical的代码段正在被0线程执行时,1线程的执行也到达该代码段,则它将被阻塞知道0线程退出临界区。
使用并行规约的并行程序
#include <stdio.h>
#include <omp.h>
#define NUM_THREADS 2
static long num_steps = 100000;
double step;
void main ()
{
int i;
double pi = 0.0, sum = 0.0, x = 0.0;
step = 1.0 / (double)num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel for reduction(+:sum) private(x) //每个线程保留一份私有拷贝sum,x为线程私有,最后对线程中所以sum进行+规约,并更新sum的全局值
for(i = 1; i <= num_steps; i++){
x = (i - 0.5) * step;
sum += 4.0 / (1.0 + x * x);
}
pi = sum * step;
printf("%lf\n",pi);
} //共2个线程参加计算,其中线程0进行迭代步0~49999,线程1进行迭代步50000~99999.
PSRS排序
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<omp.h>
#define INF 2147483647
#define NUM_THREADS 3
/**************************************************
* 合并两个已排好序的子数组A[l : m], A[m + 1 : r], 写回A[l : r]
***************************************************/
void Merge(int *A, int l, int m, int r){
int i, j, k, n1 = m - l + 1, n2 = r - m;
int *L = (int *)malloc((n1 + 1) * sizeof(int));
int *R = (int *)malloc((n2 + 1) * sizeof(int));
for(i = 0; i < n1; i++) L[i] = A[l + i];
for(j = 0; j < n2; j++) R[j] = A[m + 1 + j];
L[i] = R[j] = INF;
i = j = 0;
for(k = l; k <= r; k++) if(L[i] <= R[j]) A[k] = L[i++]; else A[k] = R[j++];
free(L); free(R);
}
/**************************************************
* 对A[l : r]进行归并排序
***************************************************/
void MergeSort(int *A, int l, int r){
if(l < r){
int m = (l + r) / 2;
MergeSort(A, l, m);
MergeSort(A, m + 1, r);
Merge(A, l, m, r);
}
}
/**************************************************
* 对A[0 : n - 1]进行PSRS排序
***************************************************/
void PSRS(int *A, int n){
int id;
int per = n / NUM_THREADS; //A的n个元素划分为NUM_THREADS段,每个处理器处理per个元素
int sample[NUM_THREADS * NUM_THREADS]; //正则采样数为 NUM_THREADS * NUM_THREADS
int pivot[NUM_THREADS]; //NUM_THREADS - 1 个主元,最后一个设为INF,作为哨兵
int *A2[NUM_THREADS][NUM_THREADS] = {NULL}; //数组,NUM_THREADS处理器把自己的per个元素划分为NUM_THREADS段
int A2len[NUM_THREADS][NUM_THREADS] = {0}; //上面数组的实际存储长度,每个处理器的每个段的元素个数
omp_set_num_threads(NUM_THREADS);
#pragma omp parallel private(id) shared(per, A, A2, n, sample, pivot, A2len) //NUM_THREADS 个处理器同时执行,共用代码
{
id = omp_get_thread_num(); //当前处理器的id
//(1)均匀划分 (2)每个处理器进行局部串行归并排序
MergeSort(A, id * per, (id + 1) * per - 1);
//(2)正则采样,每个处理器分别选出 NUM_THREADS 个样本,共 NUM_THREADS * NUM_THREADS 个
for(int k = 0; k < NUM_THREADS; k++)
sample[id * NUM_THREADS + k] = A[id * per + k * per / NUM_THREADS];
#pragma omp barrier //设置路障,同步所有线程
//(3)采样排序 (4)选择主元
#pragma omp master //主线程执行,其他线程不执行
{
MergeSort(sample, 0, NUM_THREADS * NUM_THREADS - 1); //对采样的NUM_THREADS * NUM_THREADS个样本进行排序
for(int k = 0; k < NUM_THREADS - 1; k++) //选出NUM_THREADS - 1个主元
pivot[k] = sample[(k + 1) * NUM_THREADS];
pivot[NUM_THREADS - 1] = INF; //哨兵
}
#pragma omp barrier
//(5)主元划分
for(int k = 0; k < NUM_THREADS; k++)
A2[id][k] = (int *)malloc(sizeof(int) * per * 2); //每个处理器的每个段的数组申请空间,最长不会超过 2 * per 个
for(int k = 0, j = id * per; j < id * per + per; j++){ //每个处理器对自己的per个元素按主元划分为NUM_THREADS段
if(A[j] < pivot[k]){ //这里如果不用哨兵,最后一段要单独考虑
A2[id][k][A2len[id][k]++] = A[j];
}
else{
k++;
A2[id][k][A2len[id][k]++] = A[j];
}
}
#pragma omp barrier //这里必须有路障,否则部分处理器先划分结束后就开始全局交换,但此时数据还没有准备好
//(6)全局交换
//每个处理器把自己的per个元素划分成的NUM_THREADS个段“发送”给对应的NUM_THREADS个处理器(除了对应自己的那段)
//实际上是每个处理器主动去其他处理器的per里取来自己的那段
for(int k = 0; k < NUM_THREADS; k++){
if(k != id){ //A2[id][id]是每个处理器对应自己的那段
memcpy(A2[id][id] + A2len[id][id], A2[k][id], sizeof(int) * A2len[k][id]);//从其他处理器那里获取自己的那段直接接在后面
A2len[id][id] += A2len[k][id];
}
}
//(7)每个处理器归并排序
MergeSort(A2[id][id], 0, A2len[id][id] - 1);
#pragma omp barrier
//(8)A2写回A
#pragma omp master //主线程执行,其他线程不执行
{
for(int j = 0, k = 0; k < NUM_THREADS; k++){
memcpy(A + j, A2[k][k], sizeof(int) * A2len[k][k]);
j += A2len[k][k];
}
}
#pragma omp barrier
//销毁A2动态申请的空间
for(int k = 0; k < NUM_THREADS; k++)
free(A2[id][k]);
}
}
int main(){
int A[27] = {15, 46, 48, 93, 39, 6, 72, 91, 14, 36, 69, 40, 89, 61, 97, 12, 21, 54, 53, 97, 84, 58, 32, 27, 33, 72, 20};
double t1, t2;
t1 = omp_get_wtime();
PSRS(A, 27);
t2 = omp_get_wtime();
printf("time: %lfs\n", t2 - t1);
for(int i = 0; i < 27; i++)
printf("%d ", A[i]);
printf("\n");
return 0;
}
结果