编译原理课程实验汇报
2019-01-17
编译原理课程实验汇报
第一部分:小组合作篇
1. 实验内容
在给定框架下,完成一个PL0语言的简单编译器
预备实验
- 安装Linux系统
- 安装GCC/Git/CMake
- 学习使用git命令合作编写代码
Lab1
- 熟悉PL0语言词法
- 实现语法分析部分,对输入的文件实现Token流输出
Lab2
熟悉PL0语言的语法图
实现语法分析部分
使用递归下降的方式
产生语法树
部分错误的检测
Lab3
- 更完整的错误检测与处理
- 对PL0语言进行拓展
- 设计并绘制新的语法图
Lab4
- 完善Lab3添加的功能
- 实现生成中间代码(基于特定模型的虚拟机)
2. 总体设计和实现功能
- 根据助教所给的框架,主要包括以下几部分
- common部分定义了编译器相关的数据结构和全局变量
- err部分定义了错误了类型对应的提示信息
- lex部分实现词法分析,输入文件字符流,构建一个状态机进行分析,输出Token流
- syntax部分实现语法分析和代码生成。调用lex,逐个读取Token,进行递归下降的语法分析,用语法制导的方式生成中间代码
- test.c
- 使用以上几部分构建编译器
- 前期用于测试
- 最后用于生成一个PL0编译器,调用时两个参数分别为输入的PL0源代码文件和输出的中间代码文件,该中间代码可在助教提供的PL0虚拟机上运行
- 最后在助教的虚拟机上运行得分为124
3. 小组成员之间的合作形式
- 每次实验我先完成了一大部分
- 在我的万般催促下,在每周日下午会面讨论,我和组长继续完善代码
- DDL前一天由我收尾
4. 对小组合作效果进行评价
- 合作效果其实不大
- 组长忙于其他课程,不过与我讨论很多;另一位同学就划水了…-_-
- 大部分代码都是由我完成
第二部分:个人任务篇
1. 我的主要任务
- 词法的全部实现
- 语法的大部分实现(除了错误处理的细节)
- 生成代码部分的几乎全部(除了call的一部分代码)
- 绘制新的语法图
2. 每一个任务的完成
词法部分
PL0Lex_get_token函数每次被调用时,顺序读入文件中的字符,直到得到一个token或着发现语法错误不进行复杂的判断,而是预先构造状态转换表,实现了一个有限自动机
- 包括非接受状态集和接受状态集
- 一开始进入
START状态,然后进入一个while循环,每次读入一个字符后根据状态转换表进行转换 - 若读取的字符类型为
ILLEGAL,直接返回错误类型。 - 如果进入了接受状态则返回token及其类型,长度,行号,位置
- 如果进入非接受状态,则循环继续,但要注意对数字和标识符以及长度进行记录,以便后续返回
- 如果读取到数字,则进入
IN_NUM状态,继续读到数字则保持该状态,读到其他类型字符则进入NUM_AC状态。 - 如果读取到字母,则进入
IN_ID状态,继续读到数字,字母和下划线则保持该状态,读到其他类型字符则进入ID_AC状态。 - 对于长度为2的symbol
- 对于各比较运算符
<=和>=,读到第一个字母时,进入一个选择状态,根据下一个字符是否为=来进入相应接受状态,注意是否回退一个字符。 - 对于
!=和:=,读取第一个字符时,分别进入选择状态,如果下一个字符是=,则接受,否则,第一个字符是非法字符,报错。
- 对于各比较运算符
- 对于剩下各个长度为1的symbol,读到该字符就进入对应symbol的接受状态
- 对于注释,读取到
/,进入一个选择状态,如果下一个字符是*则进入注释状态,否则接受/。退出注释状态同理。
- 如果读取到数字,则进入
- 如果当前的状态是
IN_LINECOMMENTS则忽略一切字符直到读取到换行符\n - 如果当前的状态是
IN_BLOCKCOMMENTS则忽略一切字符直到读取到*/
关于是否回退一个字符,预先设置一个数组来查询。
关于保留字,不在状态表中体现,进入
ID_AC后取得一个字符串,此时才与保留字数组进行比较,如果不属于其中任何一个,则认为是标识符。关于状态转换表
二维表,实现上面描述的自动机的功能,给定当前状态和输入字符,得到下一个状态
为了使状态表不会太大,对字符进行分类,改为根据当前状态和当前输入的字符类型进行转换
- 数字类型
- 字母类型
- 分隔符类型
- 长度为1的symbol字符每种对应一个类型
- 长度为2的symbol中出现的额外字符
!和:也作为两种类型 - 其他字符均视为非法字符类型。
字符类型定义
typedef enum _tCharType{ LETTER, /* A-Za-z_ */ DIGIT, /* 0-9 */ SPACE, /* */ TAB, /* \t */ NEWLINE,/* \n */ PLUS, /* + */ MINUS, /* - */ TIMES, /* * */ SLASH, /* / */ EQU, /* = */ LES, /* < */ GTR, /* > */ LPAREN, /* ( */ RPAREN, /* ) */ COMMA, /* , */ SEMICOLON,/* ; */ PERIOD, /* . */ COLON, /* : */ EXCLAMA,/* ! */ AND, /* & */ OR, /* | */ ILLEGAL /* other */ } CharType;状态定义
typedef enum _tState{ START, SLASH_SEL, LES_SEL, GTR_SEL, IN_NUM, IN_ID, IN_LINECOMMENTS, IN_BLOCKCOMMENTS, TO_END_BLOCKCOMMENTS, COLON_SEL, EXCLAMA_SEL, AND_SEL, OR_SEL, //以上是中间状态(非接受) PLUS_AC, MINUS_AC, TIMES_AC, SLASH_AC, EQU_AC, NEQ_AC, LES_AC, LEQ_AC, GTR_AC, GEQ_AC, LPAREN_AC, RPAREN_AC, COMMA_AC, SEMICOLON_AC, PERIOD_AC, BECOMES_AC, NOT_AC, AND_AC, OR_AC, NUM_AC, ID_AC, //以上是接受状态 ERROR1,// ":" expect "=" ERROR2,//expect "&&" but find "&" ERROR3 //expect "||" but find "|" } State;
语法部分
- 使用递归下降的方式
- 实现拓展语法
- 增加逻辑运算符
&&||!- 将PL/0语言中的“条件”概念一般化 (表达式值非零即为“真”)
- 短路计算
- 加入
return语句 - 增加
elseelif - 增加
dowhile - 增加参数传递
- 在语法分析中引入负数
- 增加逻辑运算符
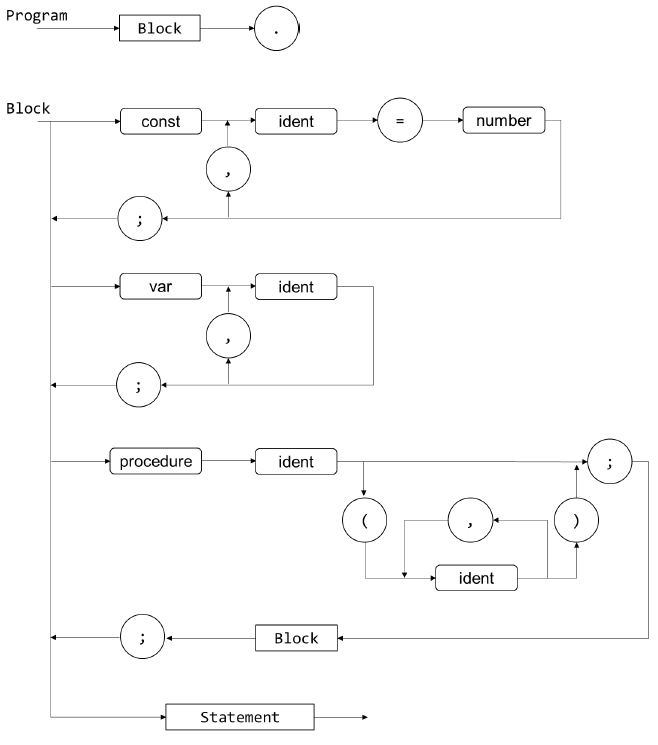
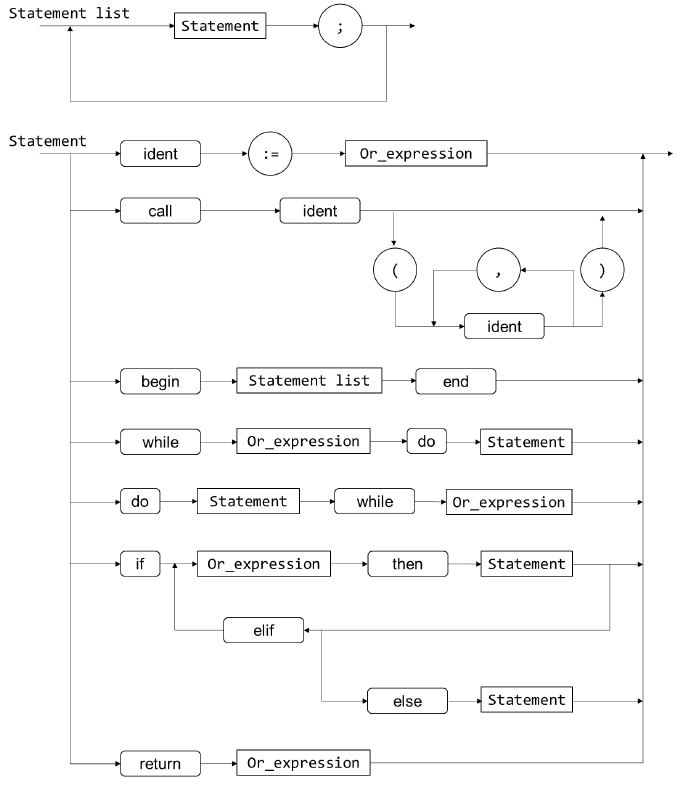
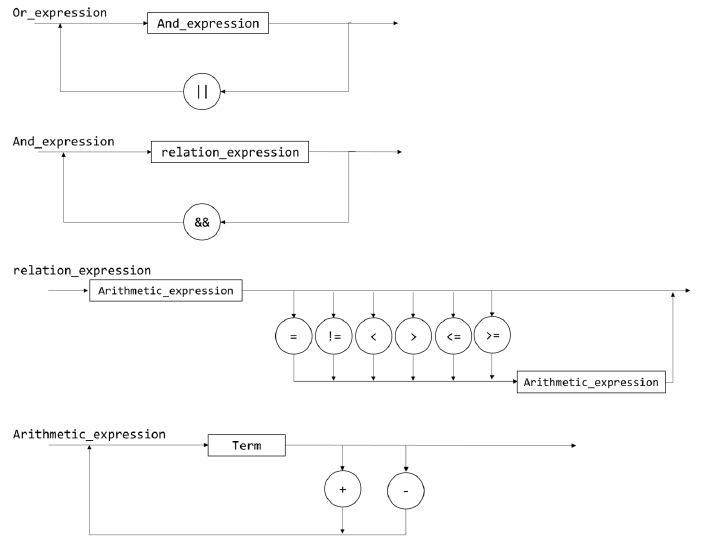
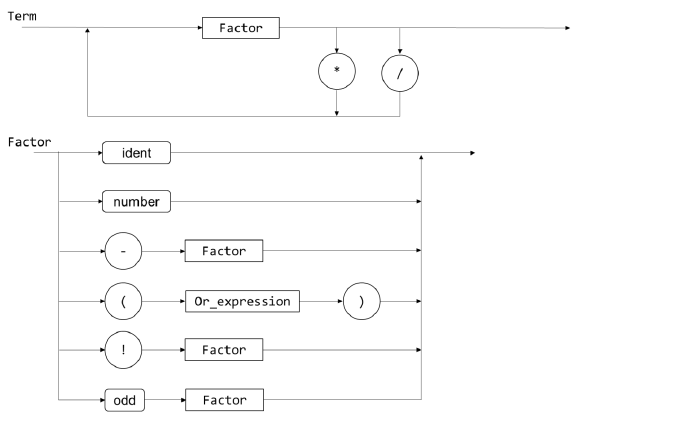
- 语法图如下
- 根据语法图实现上述非终结符对应的函数
programprogram_blockvar_declarationconst_declarationstatementor_expressionand_expressionrelation_expressionarithmetic_expressiontermfactor
- 其他函数
gettoken:调用词法分析器,获取一个Tokenmatch:比较当前Token与预期的(通过参数传入)是否一致table_append:将一个标识符加入全局表中table_append2:将一个标识符(参数)加入另一个全局表中intable:查找一个标识符在上面两个表中的下标,包括变量/常量/过程名/参数名
- 错误检测恢复的实现
- 发现当前Token不是预期的时候,即跳过后面的若干个Token,直到下一个可以正确地跟随当前正在分析的句子结构的符号为止。
- 对于上面的每个函数(对应语法图的每一个分析过程),调用时提供一个显式参数(一个集合),它指明当前活动结点的可能的后继符号集合,这个集合由上层的函数计算。
- 后继符号集合计算
- 在最上层先用一些明显的关键符号给它赋初值
- 随着分析的层次深入,逐步补充别的合法符号
- 在
statement和factor的开始和结束时进行检测(调用check函数)- 因为这两个函数出现大量分支,需要对开始符号进行检测。
- 其他层次的函数最终都会通过层层次调用在这两个函数里发现错误。
check函数实现- 有三个参数:
- 允许的下一个符号集合S1
- 另加的停止符号集合S2,有些符号的出现,虽然无疑是错的,但绝不应被忽略而跳过
- 应该报的错误信息
- 如果当前Token不在集合S1中,即报错,此时合并S1和S2为S,继续读取Token,直到找到一个Token在S中
- 这个函数可使分析程序不会盲目地跳过后面的符号
- 有三个参数:
生成代码部分
全局数组
codes,存储全部代码每条代码有两个参数,第一个参数是指令名称,第二个参数用于
PUT的常数或者JMP的目标地址,其他指令的第二个参数为NONE(预先定义的一个值)typedef struct _code{ char ins[4]; int para; }code;
gen函数,用于每次生成一条代码PL0虚拟机包括3部分,codeheap/stack/memory
这里,stack只作为运算使用,当前运算总是对stack顶端的一个或两个值进行操作(虚拟机指令决定了这个特性)
memory被划分为两部分,从低地址端memory[1]开始增长作为模拟的运行栈(runstack),从高地址端memory[1023]开始递减作为寄存器
--------------men[0] |null |runstack |.. |.. <-- runstack's top(REG_SP) | |reg4 //REG_SP |reg3 //REG_BP |reg2 //REG_BX |reg1 //REG_AX --------------men[1023] a record in runstack (running) --------------low address |return value |return address(in codeheap) |parameters |old base <---base (REG_BP) |local id(var/const/procedure) --------------high address <---top (REG_SP)
用虚拟机的指令以及memory模拟一个运行栈和寄存器组,实现以下函数
gen_savereg(REG regid)函数,将stack栈顶值保存到上面的某个寄存器gen_loadreg(REG regid)函数,将上面的某个寄存器的值读取到stack栈顶gen_runstack_push,包括3个函数,向运行栈中压入一个值,这个值可以是立即数/来自寄存器/来自stack栈顶gen_runstack_pop,包括2个函数,从运行栈取出栈顶值,这个值可以被扔掉/保存到寄存器gen_exchangestacktop,交换stack栈顶的两个值- 先存到”寄存器“
- 再反序压入
gen_int2bool,将stack栈顶值转为bool值- 非0值即为1
- 实现:先
PUT 0,再EQ,最后NOT
gen_id_addr(int index),根据标识符表/参数表的下标,动态生成某个变量/常量/参数在运行栈中相对基址的偏移量,然后加上基址,得到在memory中的地址,将这个地址放到stack栈顶- 基址是随程序运行栈的变化而变化的
- 偏移量在生成代码时就算好了,根据语法分析时加入变量表和参数表的下标
- 运行栈中当前基址之下是参数(偏移量为负)
- 运行栈中当前基址之上是局部变量(偏移量为正)
主要功能与拓展功能的实现
- 增加逻辑运算符
&&||!- 上面语法部分把
expression和condition拓展为4个层次or_expression,and_expression,relation_expression,arithmetic_expression - 将PL/0语言中的“条件”概念一般化 (表达式值非零即为“真”)
arithmetic_expression计算算术表达式得到的值向上面3层传递时- 如果上面3层只有都一个运算数,这个值被保留,即作为最终or_expression的值
- 如果某层有多个参数,则转换为bool值(0/1)再继续运算,调用
gen_int2bool实现
- 短路计算
or_expression第一个数为1时,生成JMP指令(参数先空着),跳过之后多个值的计算,这里使用回填技术,在生成后面的计算代码后,再将代码所在的行填到这里JMP的参数and_expression第一个数为0时,同理
- 上面语法部分把
- 加入
return语句,增加参数传递factor和statement中分析call时,利用gen_runstack_push函数完成- 生成*”将返回地址(当前代码下标+1)压入运行栈”*的代码
- 再生成*”将参数依次压入运行栈”*,记下参数个数
- 然后生成“跳转到子过程开始处”的代码
- 最后按个数生成*”将参数依次弹出运行栈”*的代码。此时返回值正好在stack顶部
procedure部分,扫描到参数全部添加进另一个参数表(专门存放参数),同时将过程名称和当前代码地址加入标识符表statement中的return语句,将返回值压栈,交换栈顶两个值,则栈顶值是返回地址,生成跳转代码即可
- 增加
elseelif- 利用
JPC和JMP指令,依然使用回填技术,很简单
- 利用
- 增加
dowhile- 同上
- 负数
- 不在词法分析中实现
const_declaration取得常量数字Token时,如果前面一个Token是减号,则数取反后再存入加入标识符表factor中,根据语法图,识别到负号时,再次调用factor,结果在栈顶,此时再生成两条代码PUT 0; SUB;实现将栈顶值取反
- 增加逻辑运算符
3. 遇到的困难及解决
- 行号的计算问题
- 通过识别
\n,遇到就增加 - 但出现现象:对于某些行,行号增加了两次
- 这种情况出现在标识符是该行的最后一个Token且标识符之后就是换行符,这样,在标识符结束时会有一个回退一个字符的动作,导致
\n被扫描两次,则行号也被增加了两次。 - 为了避免回退导致
\n出现两次,应该限制\n扫描后是在START状态下,也是不回退的情况下,判断此行结束,所以判断条件改为if(ch=='\n' && state==START) - 考虑到还有块注释的情况,应该改为
if(ch=='\n' && (state==START || state==IN_BLOCKCOMMENTS))
- 通过识别
- 打印错误所在行的文本
- 最后一次实验需要打印错误所在行的文本,而之前词法分析时是每次用
fgetc读取一个字符,并没有保存当前行 - 修改读取方式,一开始用
fgets读取一行,缓存至linebuf中,每次用pos偏移获取一个字符放在全局变量ch中,如果ch==0,即读取到linebuf结束时,再使用fgets读取一行。 linebuf定义在在lex结构体中,语法分析时调用错误函数时可以使用。
- 最后一次实验需要打印错误所在行的文本,而之前词法分析时是每次用
- 错误恢复分析问题
- 一开始不知道如何下手
- 认真阅读课本中关于错误处理的部分,然后查阅了很多资料之后才大概明白如何处理
- 一些细节问题
- 有时候遇到某个错误时,反复报同一个错:处理完一个Token忘了
gettoken - 注意虚拟机的一些特性
- 比如
DIV和SUB取操作数的顺序和语法分析时的顺序时相反的,需要自行交换栈顶两个数 - 调用虚拟机打印栈顶值后并不会弹出栈顶值
NOT,AND,OR只能实现对0和1的运算,数值到布尔值的运算需要自行实现
- 比如
- 有时候遇到某个错误时,反复报同一个错:处理完一个Token忘了
4. 亮点
- 状态表的压缩(详见上面总体设计)
- 合并输入符号的类型
- 集合的表示
- 没有使用任何数据结构
- 因为集合元素是有限的Token类型,故集合大小有上限
- 直接用长整型数表示集合,每个位表示一种Token类型(类似独热编码)
- 将Token_Type(枚举类型)用2的幂映射到一个长整数
- 用位运算实现集合操作
- 创建集合:直接定义一个长整型数为0
- 合并集合:位或运算
- 元素是否在集合中:位与运算
- 错误处理
- 动态生成可能的后续符号集合
- 有选择地跳过非预期的符号
- 较好地实现错误跳过并继续分析
- 模型运行栈和寄存器
- 虚拟机提供的栈只能实现简单运算,无法深入到栈中获取数据
- 在内存中模拟运行栈,用生成的代码去”操作“运行栈
- 动态地在向栈中加入活动记录,实现过程的递归调用
5. 总结与心得体会
- 通过实验,我能更深入理解上课所学的理论知识
- 词法:有限状态机
- 语法:递归下降预测分析
- 生成代码:语法制导的翻译,回填技术
- 错误处理:First集,Follow集
- 熟悉了git的使用
- 体会到了编译器编写的困难
- 检测到错误之后要能继续分析,lab2和lab3大部分时间都在想这个问题
- 这只是一个小小的实验,实现前端的一些简陋功能,但它已经花费了很长时间
- 如果面对更复杂的语法,就需要借助生成器,如书上所讲的Yacc
- 如果再考虑语言的各种特性(面向对象、多态、重载),那就更困难了
- 编译器生成代码要针对”体系结构“,这里就是助教提供的虚拟机
- 体会到大型工程管理不易
- 需要编织好划分好每个文件的功能
- 处理好全局变量、外部变量,避免重复定义,功能冗余