题目
图搜索BFS算法及存储优化
实验要求:
1.模拟数据集
自己随机生成有向图,边数的规模为10,100,1000,10000,100000;
进行BFS搜索,记录程序完成时间和所需内存空间大小。
2.真实数据集
https://pan.baidu.com/s/1pvfphiywjSXohO-bSnL1HA
数据集说明:均为twitter真实数据集,数据集规模如下:
twitter_small: Nodes 81306, Edges 1768149, 有向图;
twitter_large: Nodes 11316811, Edges 85331846, 有向图。
进行BFS搜索,设计存储优化方案和加速方案,记录程序时间和内存空间大小。
实验说明
1)编程语言和实验平台不限,可考虑并行(i.e., GPU/OpenMP/MapReduce);
2)至少需完成模拟数据集和twitter_small数据集的实验,twitter_large数据集为加分题。
算法设计
BFS算法
BFS(Breadth First Search),即广度优先搜索,从某个结点s开始,自始至终一直通过已找到和未找到顶点之间的边界向外扩展,就是说,算法首先搜索和s距离为k的所有顶点,然后再去搜索和S距离为k+l的其他顶点。该算法需要一个先进先出队列,只要队列不为空,就从队首取出一个结点n,访问它的所有邻居,如果某个邻居未被标记为已访问(visit=0),则将该邻居加入到队列尾,最后将该结点n标记为已访问(visit=1)。
BFS的时间复杂度为O(V+E),V为结点数,E为边数。因为每个结点都进入队列一次,访问邻居时每条边至多被扫描一遍。
存储结构
由于结点数很多且边稀疏,故采用邻接表进行存储,定义两种结构体:
nbnode,表示一个结点的某个邻居
- p,int类型,该邻居在结点数组中的下标
- next,nbnode*类型,指向下一个邻居
node,表示一个结点
- id,int类型,表示从文件中读取到的结点ID
- visit,char类型(节省存储),-1表示不存在该结点,0表示结点存在但未访问,1表示存在且已访问。
- nblisthead,nbnode*类型,指向第一个邻居
全局开设一个node结点数组arr
对于twitter_small.txt文件,81306个结点,其id最大达到九位数,且不连续,直接作为数组下标将造成数组过大,空间浪费多,因此使用c++的map容器,将id映射到数组下标p,每次读入一个id时,用map查询是否存在,若不存在,将该id和当前未分配的最小数组下标(即nodecount)加入map,然后nodecount++。另外,该文件中有重复边,每次为一个结点添加邻居之前先遍历链表判断是否已存在。在BFS时,访问数组直接使用下标,不再使用id。
对于twitter_large.txt,其id最大值等于结点数11316811,id连续,可以直接作为数组下标,且文件中无重复边,可以直接添加邻居无需判断重复。为了实现对node的计数,起使时visit设为-1,读取文件时,如果该结点visit=-1,则nodecount++,并且让visit=0,表示该结点存在(但未访问)。
结果
使用bfs_random.cpp测试10.txt 100.txt 1000.txt 10000.txt 100000.txt
以上5个文件由GenGraph.py生成。
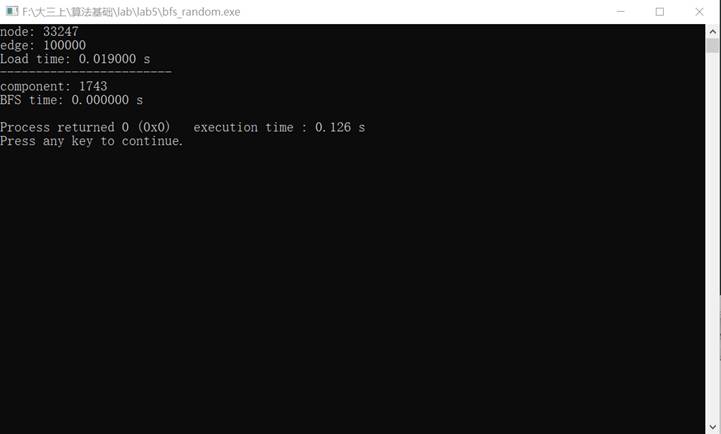
100000.txt结果如下
读取时间0.019秒,bfs时间几乎为0,内存为5.8MB(不准确,这是包括运行窗口等其他资源使用的内存)

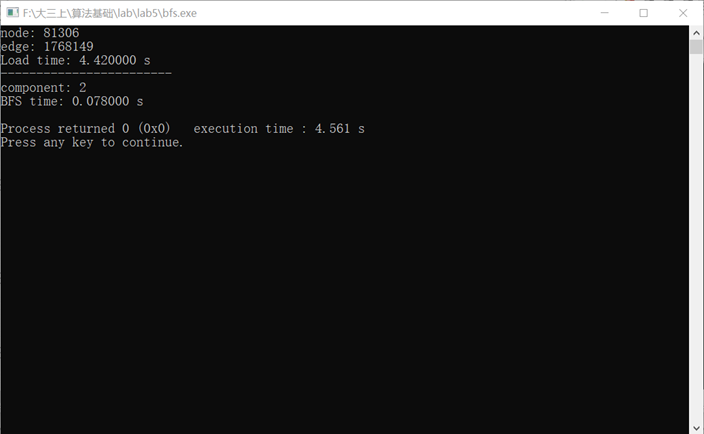
使用bfs.cpp测试twitter_small.txt
文件有重复边,序号连续,81306个结点(序号最大有9位数),1768149条边(但文件有2000000多行)
结果如下
4.5秒完成(其中读取4.4秒,bfs小于0.1秒)
内存约36MB

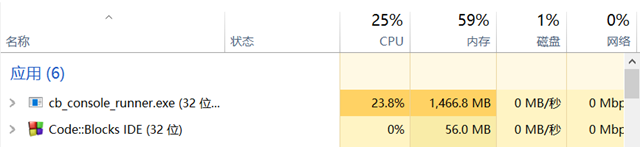
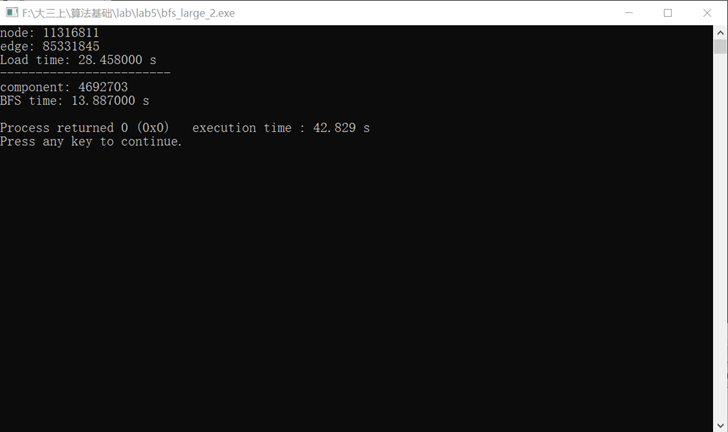
使用bfs_large_2.cpp测试twitter_large.txt
文件无重复边,序号连续,11316811个结点(最大序号就是11316811),85331845条边
结果如下
42秒完成(其中读取29秒,bfs13秒)
内存约1466MB
代码
small
#include <cstdio>
#include <ctime>
#include <cstdlib>
#include <map>
#include <queue>
using namespace std;
typedef struct _nbnode{
int p;//该邻居在表中的下标
struct _nbnode *next;
_nbnode(int _p):p(_p){}
}nbnode,*nblist;
typedef struct _node{
int id;
char visit;
nblist nblisthead;
_node(){
visit = 0;
nblisthead = NULL;
}
}node;
node *arr = new node[90000];//结点表
map<int,int> nodemap; //id 映射到 p
int edgecount = 0,nodecount = 0;
void bfs(int p){
queue<int> q;
q.push(p);
arr[p].visit = 1;
while(!q.empty()){
nbnode *nb = arr[q.front()].nblisthead;
while(nb != NULL){
if(!arr[nb->p].visit){
q.push(nb->p);
arr[nb->p].visit = 1;
}
nb = nb->next;
}
q.pop();
}
}
void BFS(){
int componentcount = 0;
for(int i = 0;i < nodecount;i++){
if (arr[i].visit == 0){
bfs(i);
componentcount++;
}
}
printf("component: %d\n",componentcount);
}
void Load(){
FILE *fp = fopen("twitter_small.txt","r+");
nbnode *nb;
int ida,idb,pa,pb;
map<int,int>::iterator itera,iterb;
while(fscanf(fp,"%d",&ida) != EOF){
fscanf(fp,"%d",&idb);
if((itera = nodemap.find(ida)) != nodemap.end()){
pa = itera->second;
}
else{
nodemap[ida] = nodecount;//向map中插入(ida,nodecount)
pa = nodecount++;
arr[pa].id = ida;
}
if((iterb = nodemap.find(idb)) != nodemap.end()){
pb = iterb->second;
}
else{
nodemap[idb] = nodecount;
pb = nodecount++;
arr[pb].id = idb;
}
nb = arr[pa].nblisthead;
while(nb != NULL){
if(nb->p == pb)//该边已存在
goto LABEL;
nb = nb->next;
}
nb = arr[pa].nblisthead;
arr[pa].nblisthead = new nbnode(pb);
arr[pa].nblisthead->next = nb;
edgecount++;
LABEL:;
}
printf("node: %d\n",nodecount);
printf("edge: %d\n",edgecount);
}
int main(){
clock_t t1,t2,t3,t4;
t1 = clock();
Load();
t2 = clock();
printf("Load time: %lf s\n",(double)(t2-t1)/CLK_TCK);
printf("------------------------\n");
t3 = clock();
BFS();
t4 = clock();
printf("BFS time: %lf s\n",(double)(t4-t3)/CLK_TCK);
return 0;
}
large
#include <cstdio>
#include <ctime>
#include <cstdlib>
#include <queue>
using namespace std;
typedef struct _nbnode{
int p;//该邻居在表中的下标
struct _nbnode *next;
_nbnode(int _p):p(_p){}
}nbnode,*nblist;
typedef struct _node{
int id;
char visit;
nblist nblisthead;
_node(){
visit = -1;//-1不存在该结点,0存在但未访问,1,已访问
nblisthead = NULL;
}
}node;
node *arr = new node[11500000];//结点表
int edgecount = 0,nodecount = 0;
void bfs(int p){
queue<int> q;
q.push(p);
arr[p].visit = 1;
while(!q.empty()){
nbnode *nb = arr[q.front()].nblisthead;
while(nb != NULL){
if(!arr[nb->p].visit){
q.push(nb->p);
arr[nb->p].visit = 1;
}
nb = nb->next;
}
q.pop();
}
}
void BFS(){
int componentcount = 0;
for(int i = 0;i < nodecount;i++){
if (arr[i].visit == 0){
bfs(i);
componentcount++;
}
}
printf("component: %d\n",componentcount);
}
void Load(){
FILE *fp = fopen("twitter_large.txt","r+");
nbnode *nb;
int ida,idb,pa,pb;
while(fscanf(fp,"%d,%d",&ida,&idb) != EOF){
pa = ida;
pb = idb;
if(arr[pa].visit == -1){
nodecount++;
arr[pa].visit = 0;
}
if(arr[pb].visit == -1){
nodecount++;
arr[pb].visit = 0;
}
nb = arr[pa].nblisthead;
arr[pa].nblisthead = new nbnode(pb);
arr[pa].nblisthead->next = nb;
edgecount++;
}
printf("node: %d\n",nodecount);
printf("edge: %d\n",edgecount);
}
int main(){
clock_t t1,t2,t3,t4;
t1 = clock();
Load();
t2 = clock();
printf("Load time: %lf s\n",(double)(t2-t1)/CLK_TCK);
printf("------------------------\n");
t3 = clock();
BFS();
t4 = clock();
printf("BFS time: %lf s\n",(double)(t4-t3)/CLK_TCK);
return 0;
}
random
#include <cstdio>
#include <ctime>
#include <cstdlib>
#include <queue>
using namespace std;
typedef struct _nbnode{
int p;//该邻居在表中的下标
struct _nbnode *next;
_nbnode(int _p):p(_p){}
}nbnode,*nblist;
typedef struct _node{
int id;
char visit;
nblist nblisthead;
_node(){
visit = -1;//-1不存在该结点,0存在但未访问,1,已访问
nblisthead = NULL;
}
}node;
node *arr = new node[100010];//结点表
int edgecount = 0,nodecount = 0;
void bfs(int p){
queue<int> q;
q.push(p);
arr[p].visit = 1;
while(!q.empty()){
nbnode *nb = arr[q.front()].nblisthead;
while(nb != NULL){
if(!arr[nb->p].visit){
q.push(nb->p);
arr[nb->p].visit = 1;
}
nb = nb->next;
}
q.pop();
}
}
void BFS(){
int componentcount = 0;
for(int i = 0;i < nodecount;i++){
if (arr[i].visit == 0){
bfs(i);
componentcount++;
}
}
printf("component: %d\n",componentcount);
}
void Load(){
FILE *fp = fopen("100000.txt","r+");
nbnode *nb;
int ida,idb,pa,pb;
while(fscanf(fp,"%d %d",&ida,&idb) != EOF){
pa = ida;
pb = idb;
if(arr[pa].visit == -1){
nodecount++;
arr[pa].visit = 0;
}
if(arr[pb].visit == -1){
nodecount++;
arr[pb].visit = 0;
}
nb = arr[pa].nblisthead;
arr[pa].nblisthead = new nbnode(pb);
arr[pa].nblisthead->next = nb;
edgecount++;
if(edgecount % 1000000 == 0) printf("%d\n",edgecount);
LABEL:;
}
printf("node: %d\n",nodecount);
printf("edge: %d\n",edgecount);
}
int main(){
clock_t t1,t2,t3,t4;
t1 = clock();
Load();
t2 = clock();
printf("Load time: %lf s\n",(double)(t2-t1)/CLK_TCK);
printf("------------------------\n");
t3 = clock();
BFS();
t4 = clock();
printf("BFS time: %lf s\n",(double)(t4-t3)/CLK_TCK);
return 0;
}
GenGraph.py
import random
for n in [10,100,1000,10000,100000]:
s = set()
while len(s) < n:
a = random.randint(1,int(n/3))
b = random.randint(1,int(n/3))
while a == b :
b = random.randint(1,10)
s.add((a,b))
f = open(str(n)+".txt","w")
for e in s:
f.write(str(e[0])+" "+str(e[1])+"\n")
f.close()